Another distinguished feature of the Gear Protocol is the Persistent memory approach. It is what makes development easier, removes a lot of complexity and makes protocol memory management match real-life hardware and operating systems.
Programs running in Gear Networks don’t use storage but rather their full state is persisted which ensures much less API surface for blockchain context. It avoids domain-specific language features as well as allows using much more complex language constructs — persisted boxed closures, futures compositors, etc.
The Gear Protocol uses clever memory virtualization techniques (despite vanilla Wasm does not), memory allocation and deallocation are first-class syscalls of the protocol. Memory access is also tracked and only required pages are loaded/stored. That allows heap-allocated stack frames of smart contracts stored in the blockchain’s state (typically found in futures and their compositors) to be seamlessly persisted and invoked when needed, preserving their state upon request.
Program code is stored as an immutable Wasm blob. Each program has a fixed amount of memory which persists between message-handling (so-called static area).
Gear instance holds individual memory space per program and guarantees its persistence. A program can read and write only within its own memory space and has no access to the memory space of other programs. Individual memory space is reserved for a program during its initialization and does not require an additional fee (it is included in the program's initialization fee).
A program can allocate the required amount of memory in blocks of 64KB. Each memory block allocation requires a gas fee. Each page (64KB) is stored separately on the distributed database backend, but at the run time, Gear node constructs continuous runtime memory and allows programs to run on it without reloads.
Memory parallelism
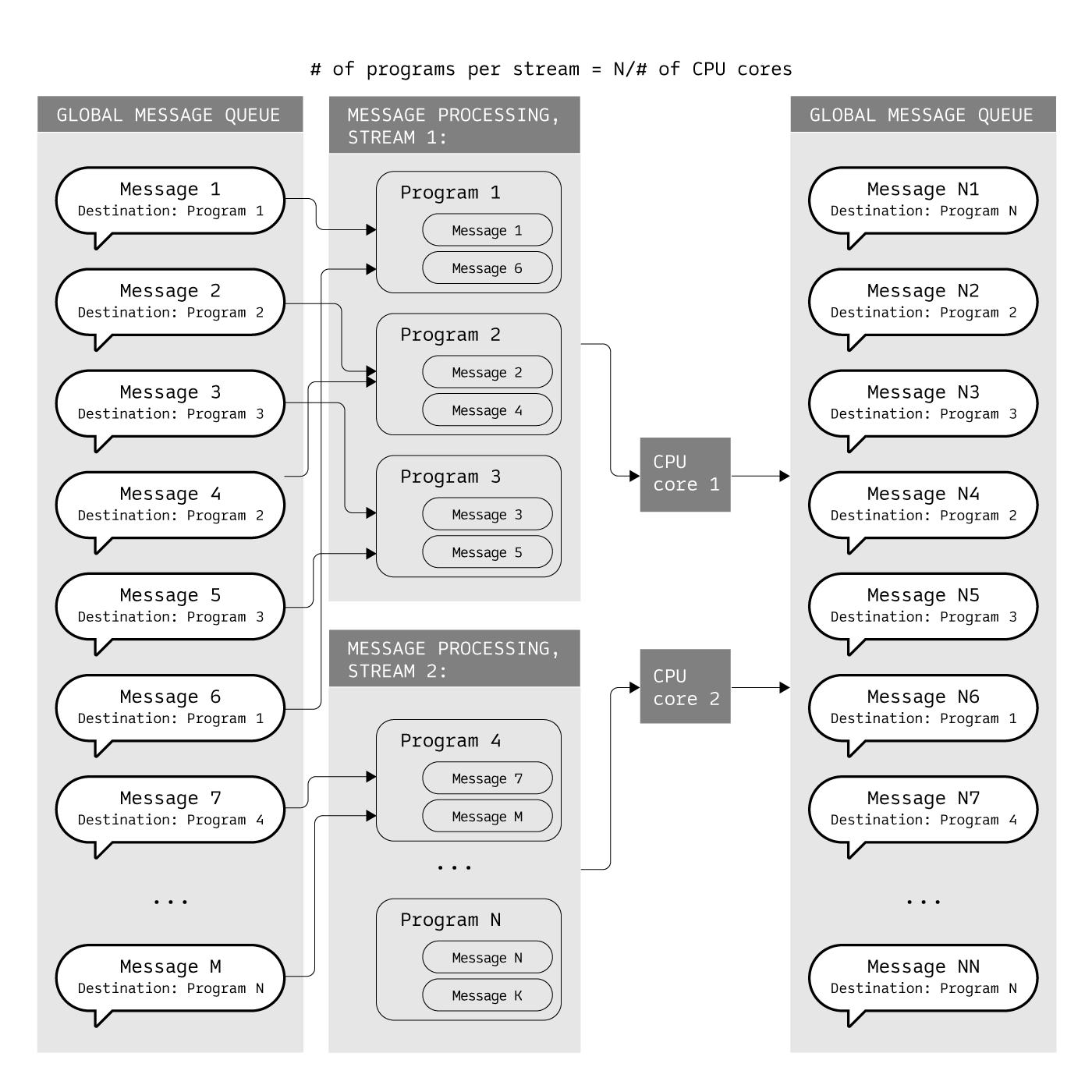
Individual isolated memory space per program allows parallelization of message processing on a Gear node. Number of parallel processing streams equals the number of CPU cores. Each stream processes messages intended for a defined set of programs. It relates to messages sent from other programs or from outside (user’s transactions).
For example, given a message queue containing messages targeted to 100 different programs, Gear node runs on a network where 2 threads of processing are configured. Gear engine uses a runtime-defined number of streams (equal to number of CPU cores on a typical validator machine), divides total amount of targeted programs to number of streams and creates a message pool for each stream (50 programs per stream).
Programs are distributed to separate streams and each message appears in a stream where its targeted program is defined. So, all messages addressed to a particular program appear in a single processing stream.
In each cycle a targeted program can have more than one message and one stream processes messages for plenty of programs. The result of message processing is a set of new messages from each stream that is added to the message queue, then the cycle repeats. The resultant messages generated during message processing are usually sent to another address (return to origin or to the next program).